

Контрольні показники



AIDA64 містить кілька тестів, які можна використовувати для вимірювання продуктивності окремих апаратних частин або системи в цілому. Це синтетичні тести, що означає, що їх можна використовувати для вимірювання теоретичної максимальної продуктивності системи. Показники пропускної здатності пам’яті, CPU та FPU створені на основі багатопоточного тестового механізму AIDA64, який, починаючи з AIDA64 Business v4.00, підтримує до 640 потоків одночасної обробки та 10 груп процесорів. Движок пропонує повну підтримку багатопроцесорних (SMP), багатоядерних технологій і технологій HyperTheading.
Кеш і дискові тести
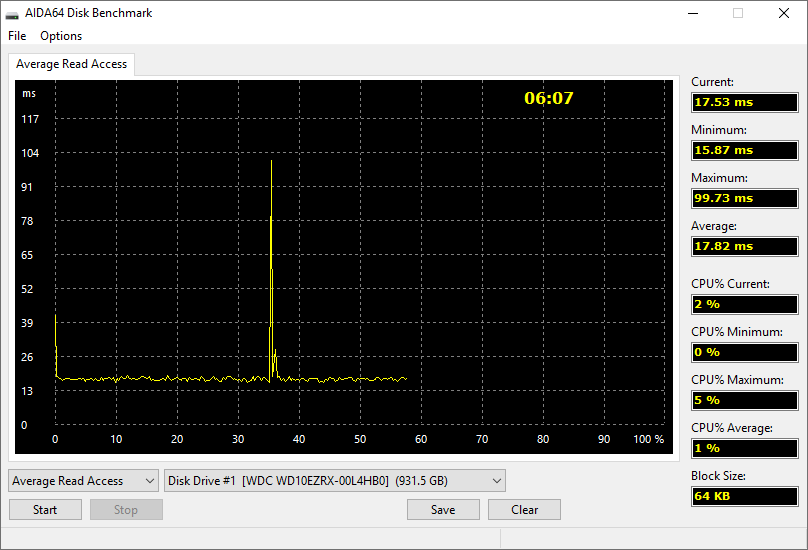
AIDA64 включає спеціальні тести для вимірювання пропускної здатності читання, запису та копіювання, а також затримки кешів і системну пам'ять. Він також має спеціальний контрольний модуль для вимірювання продуктивності пристроїв зберігання даних, зокрема (S)ATA або SCSI, жорстких дисків, масивів RAID, оптичних накопичувачів, твердотільних накопичувачів (SSD), USB-накопичувачів і карт пам’яті.
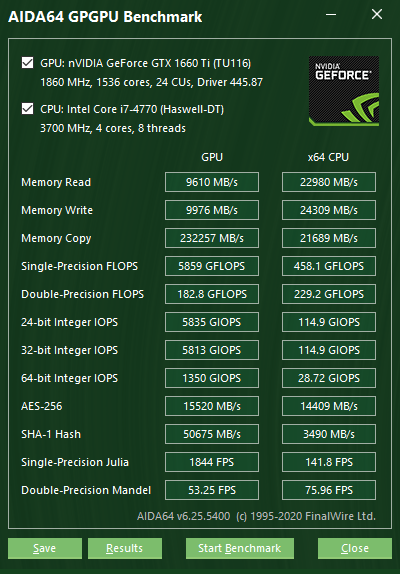
Порівняльний тест GPGPU
Ця контрольна панель, яку можна запустити з Інструменти | GPGPU Benchmark пропонує набір тестів OpenCL GPGPU. Вони призначені для вимірювання обчислювальної продуктивності GPGPU за допомогою різних робочих навантажень OpenCL. Кожен окремий тест можна запускати на до 16 графічних процесорах, включаючи графічні процесори AMD, Intel і NVIDIA, або на їх комбінації. Звичайно, повністю підтримуються конфігурації CrossFire і SLI, а також dGPU і APU. По суті, тут можна порівняти будь-який комп’ютерний пристрій, зазначений як графічний процесор серед пристроїв OpenCL.
Окрім цих комплексних тестів, AIDA64 пропонує спеціальні мікробенчмарки, які доступні в категорії Benchmark в меню Сторінка. Завдяки величезній базі даних еталонних результатів AIDA64 результати тестів можна порівняти з результатами інших конфігурацій. Наразі доступні такі мікробенчмарки:
Контрольні тести пам’яті
Території пам’яті вимірюють максимальну пропускну здатність, яку можна досягти під час виконання вибраних операцій (читання, запис, копіювання). Вони написані на Assembly і повністю оптимізовані для популярних процесорних ядер AMD, Intel і VIA за допомогою відповідних розширень набору інструкцій x86/x64, x87, MMX, MMX+, 3DNow!, SSE, SSE2, SSE4.1, AVX і AVX2.
Порівняльний аналіз затримки пам’яті вимірює типову затримку між пам’яттю і процесором. Затримка пам’яті означає час, необхідний для надходження даних до цілих регістрів ЦП після виконання команди читання.
Країн ЦП

Цей простий цілочисельний тест зосереджений на можливостях передбачення розгалужень ЦП і штрафах за помилкове передбачення гілок. Він обчислює рішення для класичної «головоломки N queens» на шаховій дошці 10x10. Теоретично, при тій самій тактовій частоті процесор з коротшим конвеєром і меншими штрафами за помилкове передбачення досягне вищих показників тесту. Наприклад, якщо HyperThreading вимкнено, процесори Pentium 4 на базі Intel Northwood досягають вищих результатів, ніж процесори Intel Prescott, оскільки перший має 20-ступінчастий конвеєр, тоді як другий має 31-ступеневий конвеєр. CPU Queen використовує цілі оптимізації MMX, SSE2 і SSSE3.
CPU PhotoWorxx

Цей цілочисельний тест вимірює продуктивність процесора за допомогою кількох алгоритмів обробки 2D-фотографій. Він виконує такі завдання на дуже великому зображенні RGB:
- Заповнює зображення випадковими кольоровими пікселями.
- Повертає на 90 градусів проти правої сторони
- Поворот на 180 градусів
- Різниця
- Перетворення колірного простору (використовується, наприклад, під час перетворення JPEG)
Тест в основному підкреслює ціле число SIMD блоки виконання арифметики ЦП, а також підсистеми пам'яті. Тест CPU PhotoWorxx використовує відповідні розширення x87, MMX, MMX+, 3DNow!, 3DNow!+, SSE, SSE2, SSSE3, SSE4.1, SSE4A, AVX, AVX2 і XOP, і це NUMA, HyperThreading, багатопроцесорний ( SMP) і багатоядерний (CMP).
CPU ZLib
Цей цілочисельний тест вимірює комбіновану продуктивність ЦП і підсистеми пам’яті за допомогою загальнодоступної бібліотеки стиснення ZLib. CPU ZLib використовує лише базові інструкції x86, у той час як він підтримує HyperThreading, багатопроцесорний (SMP) і багатоядерний (CMP).
CPU AES
Цей цілочисельний тест вимірює CPU. продуктивність за допомогою шифрування даних AES (Advanced Encryption Standard). У криптографії AES є стандартом шифрування з симетричним ключем, який сьогодні використовується в кількох інструментах стиснення, таких як 7z, RAR, WinZip, а також у рішеннях для шифрування дисків, таких як BitLocker, FileVault (Mac OS X), TrueCrypt. CPU AES використовує відповідні інструкції x86, MMX і SSE4.1, а також апаратне прискорення на процесорах VIA C3, VIA C7, VIA Nano і VIA QuadCore з VIA PadLock Security Engine; і на процесорах Intel AES-NI. Порівняльним тестом є HyperThreading, багатопроцесорний (SMP) і багатоядерний (CMP).
Хеш ЦП
Цей цілочисельний тест вимірює продуктивність ЦП за допомогою алгоритму хешування SHA1, як визначено в Публікація Федеральних стандартів обробки інформації 180-4. Код, що лежить в основі цього методу тесту, написаний на Assembly, і він оптимізований для популярних процесорів AMD, Intel і VIA, використовуючи відповідні розширення набору інструкцій MMX, MMX+/SSE, SSE2, SSSE3, AVX, AVX2, XOP, BMI і BMI2. . Тестовий тест CPU Hash апаратно прискорений на процесорах VIA C7, Nano і QuadCore з VIA PadLock Security Engine.
FPU VP8
Цей тест вимірює продуктивність стиснення відео за допомогою версії 1.1.0 Google Відеокодек VP8 (WebM). Він кодує відеокадри 1280x720 пікселів («HD ready») в режимі 1 проход зі швидкістю 8192 кбіт/с з найкращими налаштуваннями якості. Вміст кадрів генерується фрактальним модулем FPU Julia. Код, що стоїть за цим методом порівняння, використовує відповідні розширення набору інструкцій MMX, SSE2, SSSE3 або SSE4.1 і підтримує HyperThreading, багатопроцесорний (SMP) і багатоядерний (CMP).
FPU. Юлія

Цей контрольний показник вимірює єдину точність (або 32-розрядна) продуктивність з плаваючою комою за допомогою обчислення кількох фрактальних кадрів «Джулія». Код цього тесту написаний на Assembly і повністю оптимізований для популярних процесорів AMD, Intel і VIA, використовуючи відповідні розширення набору інструкцій x87, 3DNow!, 3DNow!+, SSE, AVX, AVX2, FMA і FMA4. FPU Julia підтримує HyperThreading, багатопроцесорний (SMP) і багатоядерний (CMP).
FPU Mandel

Цей тест вимірює продуктивність з плаваючою комою з подвійною точністю (або 64-розрядною) шляхом обчислення кількох фрактальних кадрів «Мандельброта». Код цього тесту написаний на Assembly і повністю оптимізований для популярних процесорів AMD, Intel і VIA за допомогою відповідних розширень набору інструкцій x87, SSE2, AVX, AVX2, FMA і FMA4. FPU Mandel підтримує HyperThreading, багатопроцесорний (SMP) і багатоядерний (CMP).
FPU SinJulia

Цей тест вимірює продуктивність з плаваючою комою з розширеною точністю (або 80-бітовою) за допомогою обчислення одного кадру модифікованого фрактала «Джулія» . Код цього тесту написаний на Assembly і повністю оптимізований для популярних процесорів AMD, Intel і VIA за допомогою тригонометричних та експоненційних інструкцій x87. FPU SinJulia підтримує HyperThreading, багатопроцесорний (SMP) і багатоядерний (CMP).